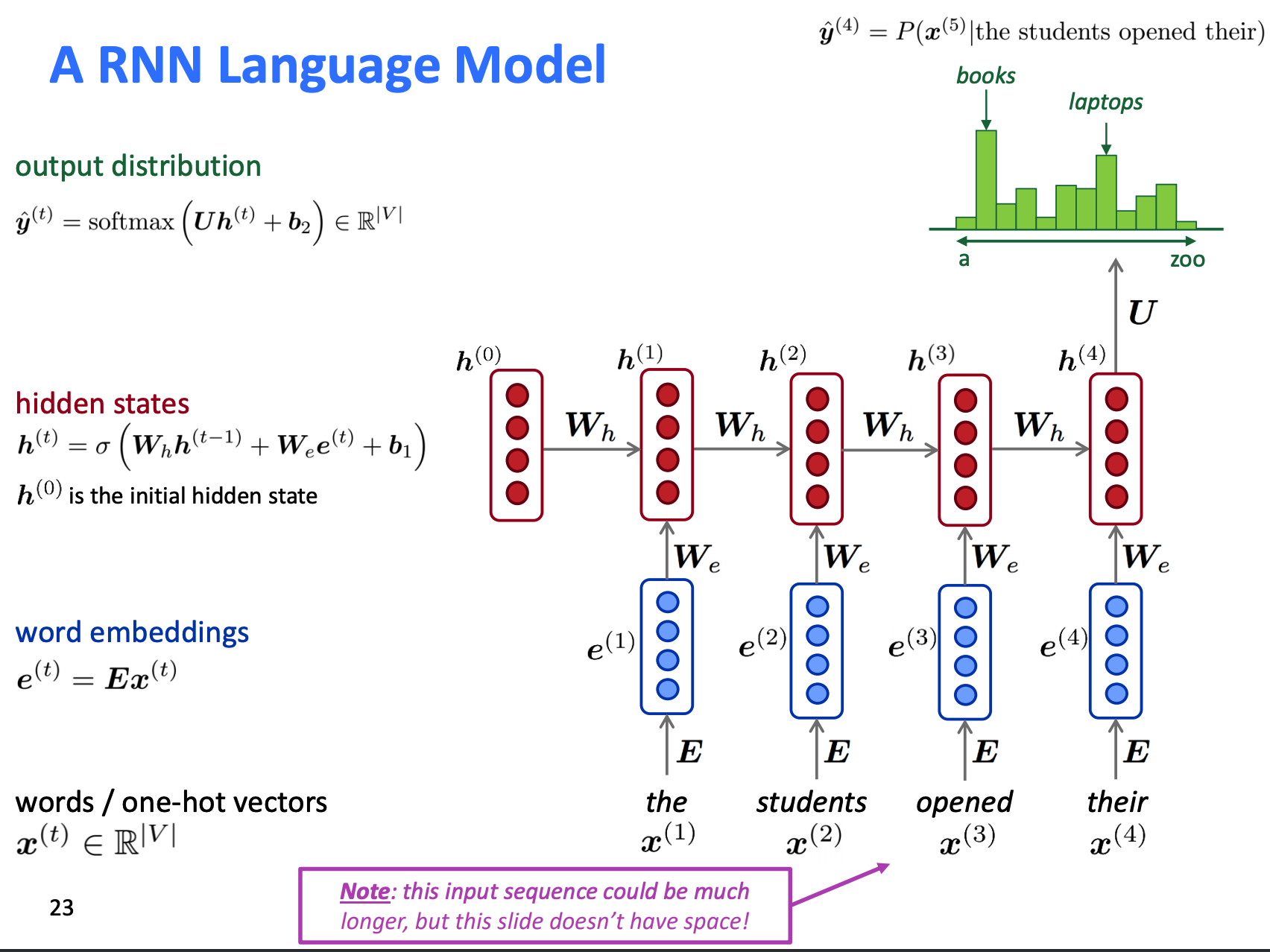
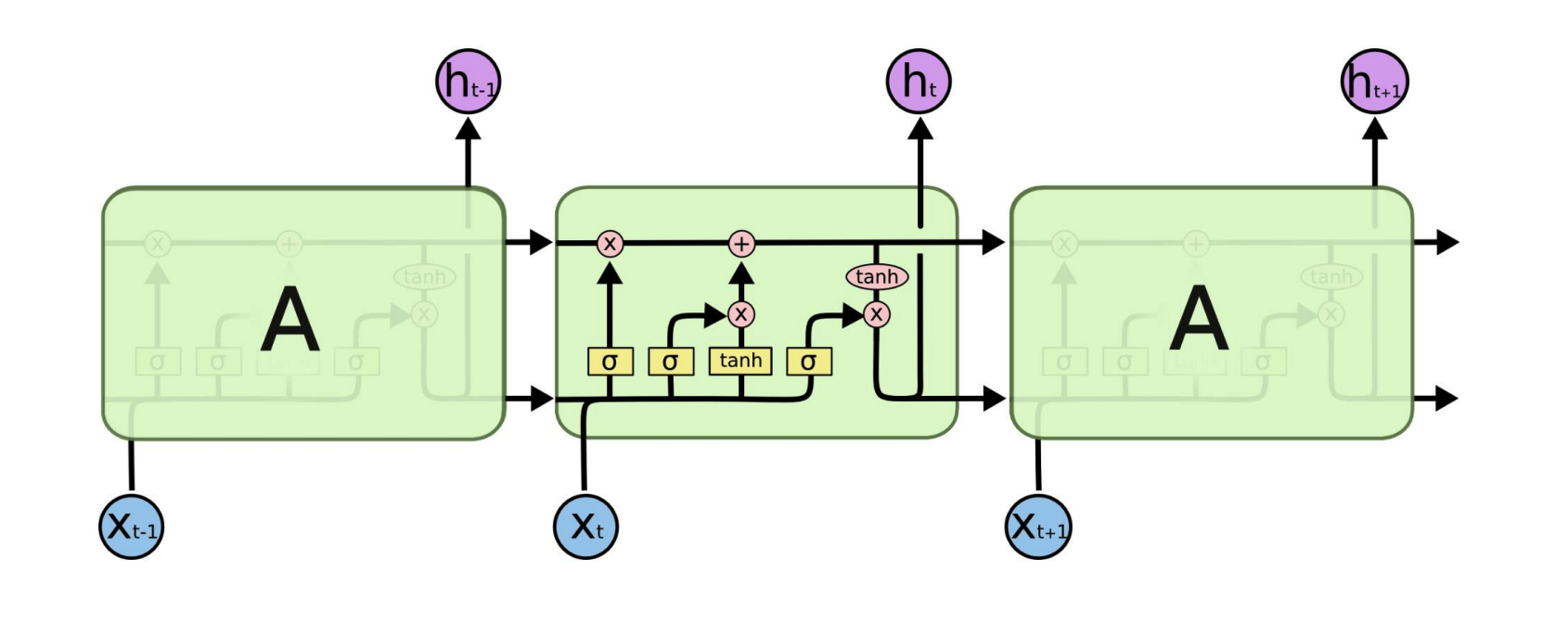
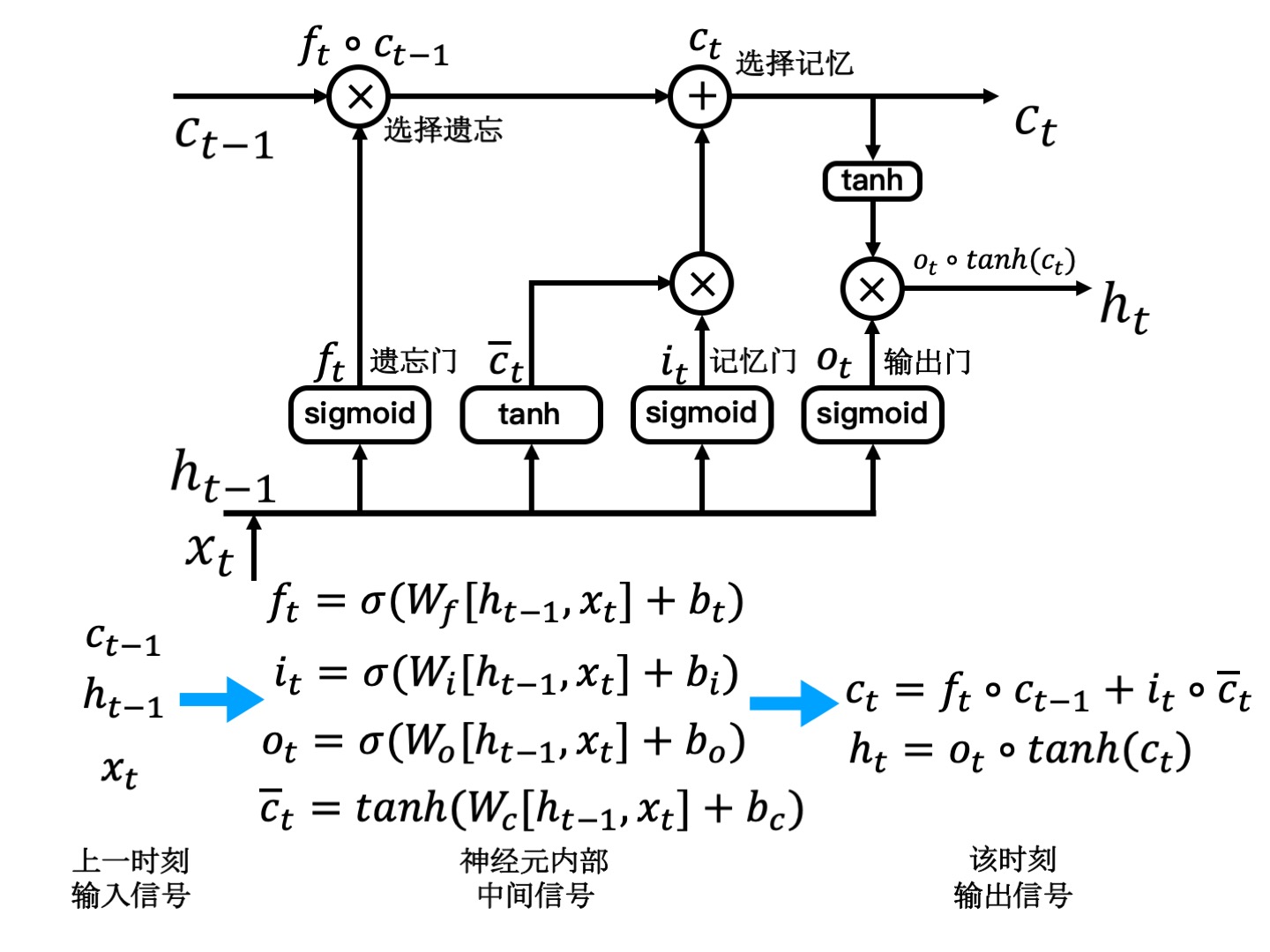
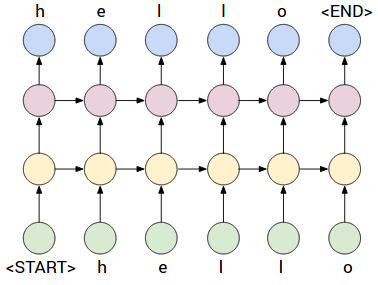
RNN & LSTM¶
 (
(

In [1]:
import itertools
import jieba
import numpy as np
from collections import Counter
from keras.models import Model, Sequential
from keras.layers import InputLayer, Embedding, LSTM, Dense, TimeDistributed, SimpleRNN
from keras.optimizers import SGD, Adam, Adadelta, RMSprop
In [2]:
def build_vocab(text, vocab_lim):
# Counter工具可以对列表对象进行计数
word_cnt = Counter(text)
# most_common(vocab_lim)可以返回一列(单词,次数)的元组
# x[0]就是把单词从元组里取出来
vocab_inv = [x[0] for x in word_cnt.most_common(vocab_lim)]
# 有了vocab_inv以后,我们可以建立它的逆映射
vocab = {x: index for index, x in enumerate(vocab_inv)}
return vocab, vocab_inv
In [3]:
vocab, vocab_inv = build_vocab(['a', 'a', 'b', 'c', 'a', 'd', 'd', 'e'], 10)
print(vocab)
print(vocab_inv)
In [4]:
def process_file(file_name, use_char_based_model):
raw_text = []
# 打开文件
with open(file_name, "r") as f:
# 遍历文件中的每一行
for line in f:
if (use_char_based_model):
# 分字
raw_text.extend([str(ch) for ch in line])
else:
# 分词
raw_text.extend([word for word in jieba.cut(line)])
return raw_text
In [5]:
def build_matrix(text, vocab, length, step):
M = []
# 将字符数组text转化为对应的编号数组M
for word in text:
# 得到word的编号
index = vocab.get(word)
if (index is None):
# 如果word不在词典里,统一编号为vocab的长度,比如vocab原来有4000个单词,它们标号为0~3999,4000是给不在词典里的词统一预留的编号
M.append(len(vocab))
else:
# 否则就取词典里的编号
M.append(index)
num_sentences = len(M) // length
X = []
Y = []
# 从0开始,每隔step个位置取一对数据
for i in range(0, len(M) - length, step):
# [M_{i}, M_{i+1}, ..., M_{i+length}]是输入
X.append(M[i : i + length])
# [M_{i+1}, M_{i+2}, ..., M_{i+length+1}]是输出
Y.append([[x] for x in M[i + 1 : i + length + 1]])
return np.array(X), np.array(Y)
In [6]:
# 设置每对数据的长度为11
seq_length = 11
# 得到文本分割后的序列,我们采用分字模型
raw_text = process_file("../input/poetry.txt", True)
# 建立词典,词频排名4000名以后的词不计入词典
vocab, vocab_inv = build_vocab(raw_text, 4000)
print(len(vocab), len(vocab_inv))
# 构建训练数据
X, Y = build_matrix(raw_text, vocab, seq_length, seq_length)
print(X.shape)
print(Y.shape)
print(X[0])
print(Y[0])
In [7]:
# 搭建模型
model = Sequential()
# 输入层 设定形状为(None,)可以使模型接受变长输入
# 注意到我们在构建训练数据的时候让每次输入的长度都是seq_length,是因为我们要用batch训练的方式来提高并行度
# 同样长度的数据可以在一次运算中完成,不同长度的只能逐次计算
# 这一层输出的形状是(seq_length, )
model.add(InputLayer(input_shape=(None, )))
# 词嵌入层,input_dim表示词典的大小,大小4000的词典一共有0~4000个标号的词,每种标号对应一个output_dim维的词向量,设置trainable=True使得词向量矩阵可以调整
# 这一层的输出形状是(seq_length, 256, )
model.add(Embedding(input_dim=len(vocab) + 1, output_dim=256, trainable=True))
# RNN层,输出形状是(seq_length, 256, )
model.add(SimpleRNN(units=256, return_sequences=True))
# 每个时刻输出的256维向量需要经过一次线性变换(也就是Dense层)转化为4001维的向量,用softmax变换转化为一个4001维的概率概率分布,第i维表示下一个时刻的词是i号单词的概率
# Dense即线性变换,TimeDistributed表示对每个时刻都如此作用
# 这一层的输出形状是(seq_length, len(vocab) + 1)
model.add(TimeDistributed(Dense(units=len(vocab) + 1, activation='softmax')))
# 定义loss函数为交叉熵,优化器为Adam,学习率为0.01
model.compile(optimizer=Adam(lr=0.001), loss='sparse_categorical_crossentropy')
model.summary()
In [8]:
# 训练
model.fit(X, Y, batch_size=512, epochs=18, verbose=1, validation_split=0.1)
Out[8]:
In [9]:
st = '明月松间照'
print(st, end='')
vocab_inv.append(' ')
for i in range(200):
X_sample = np.array([[vocab.get(x, len(vocab)) for x in st]])
pdt = (-model.predict(X_sample)[:, -1: , :][0][0]).argsort()[:4]
if vocab_inv[pdt[0]] == '\n' or vocab_inv[pdt[0]] == ',' or vocab_inv[pdt[0]] == '。':
ch = vocab_inv[pdt[0]]
else:
ch = vocab_inv[np.random.choice(pdt)]
print(ch, end='')
st = st + ch